



Duplicate data is one of the most underestimated problems in HubSpot—and it’s quietly breaking reporting, automation, and even AI.
In the first episode of Dirty Data Secrets, Jonas De Mets (Co-Founder of Koalify) sat down with Ryan Gunn, Founder of Attribution Academy and former Head of Marketing at Aptitude 8, to unpack why data quality has become a mission-critical issue for RevOps, marketing ops, and sales teams.
🎥 Watch the full episode here:
Duplicate Data: The HubSpot Problem Everyone Shares
When Ryan launched his Hubsessed newsletter, he wanted to focus on the topics HubSpot users actually care about—not what vendors assume they care about. To do this, he analyzed questions and discussions across the HubSpot Community.
One issue stood out immediately.
“Duplicate data and data quality issues were at the very top of the list.”
What makes duplicate data so challenging is that it affects everyone, regardless of company size or maturity. Startups, mid-market teams, and enterprise organizations all face the same slow decay: contacts multiply, records fragment, and confidence in the CRM erodes over time.
The problem isn’t just that duplicates exist. It’s that they accumulate silently, until they begin breaking core processes.
Why AI Raises the Stakes for Clean CRM Data
AI has rapidly become embedded across HubSpot, from reporting and forecasting to content generation and automation. While these tools promise efficiency and insight, Ryan highlights a fundamental limitation that often gets overlooked:
“AI doesn’t know the difference between clean and messy data.
It just treats everything as if it’s true.”
This creates a dangerous illusion of accuracy. AI-generated insights can sound confident and sophisticated, even when they’re based on flawed inputs.
Ryan pointed to a noticeable shift between INBOUND conferences: while INBOUND 2024 focused heavily on showcasing AI capabilities, INBOUND 2025 marked a course correction. The conversation moved back to data quality, because teams realized that without clean data, AI tools simply don’t deliver reliable results.
In short: AI doesn’t fix bad data. It amplifies it.
The Hidden Symptoms of Bad Data
Messy CRM data doesn’t always show up as obvious errors. More often, it reveals itself through subtle operational friction that teams normalize over time.
Common symptoms include:
-
Marketing and sales teams interpreting the same report differently
-
CRM data being exported into spreadsheets for “manual cleanup”
-
Reports being adjusted by a small group of experts who “know what’s wrong”
-
Leadership losing confidence in dashboards and forecasts
As Ryan explains, once teams rely on spreadsheets to correct CRM data, the CRM is no longer serving as a single source of truth. The risk becomes even greater when only one or two people understand which data is reliable.
If those people leave, the organization loses institutional knowledge, and reporting accuracy collapses.
A 2-Million-Contact Wake-Up Call
One of the most striking stories in the episode comes from a large-scale HubSpot implementation Ryan led while migrating a company from Marketo.
The project involved moving over two million contacts under an extremely tight deadline. To meet the timeline, the data was imported before it could be fully cleaned.
Before the implementation was complete, the client sent a mass email to the entire list.
The result was catastrophic:
-
A 16% bounce rate
-
40,000+ bounced emails
-
Immediate risk to email deliverability and sending reputation
“That’s more bounces than most HubSpot customers have total contacts.”
The team had to pause the entire project to focus on emergency cleanup—scanning for duplicates, validating emails, and scrubbing invalid data. While the situation was eventually stabilized, it served as a powerful reminder: data quality issues can derail even the most carefully planned projects.
Where to Start When Cleaning Up HubSpot Data
For teams overwhelmed by messy data, Ryan recommends starting with two foundational areas:
1. Email Validation
Every year, roughly 20% of contact data becomes invalid. People change jobs, abandon email addresses, or submit fake information through forms. Invalid emails hurt deliverability and skew engagement metrics.
2. Deduplication
Deduplication isn’t just about deleting extra records. When done correctly, it preserves valuable context by tying together a contact’s history across job changes, email addresses, and lifecycle stages.
Together, these two practices form the baseline for restoring trust in CRM data
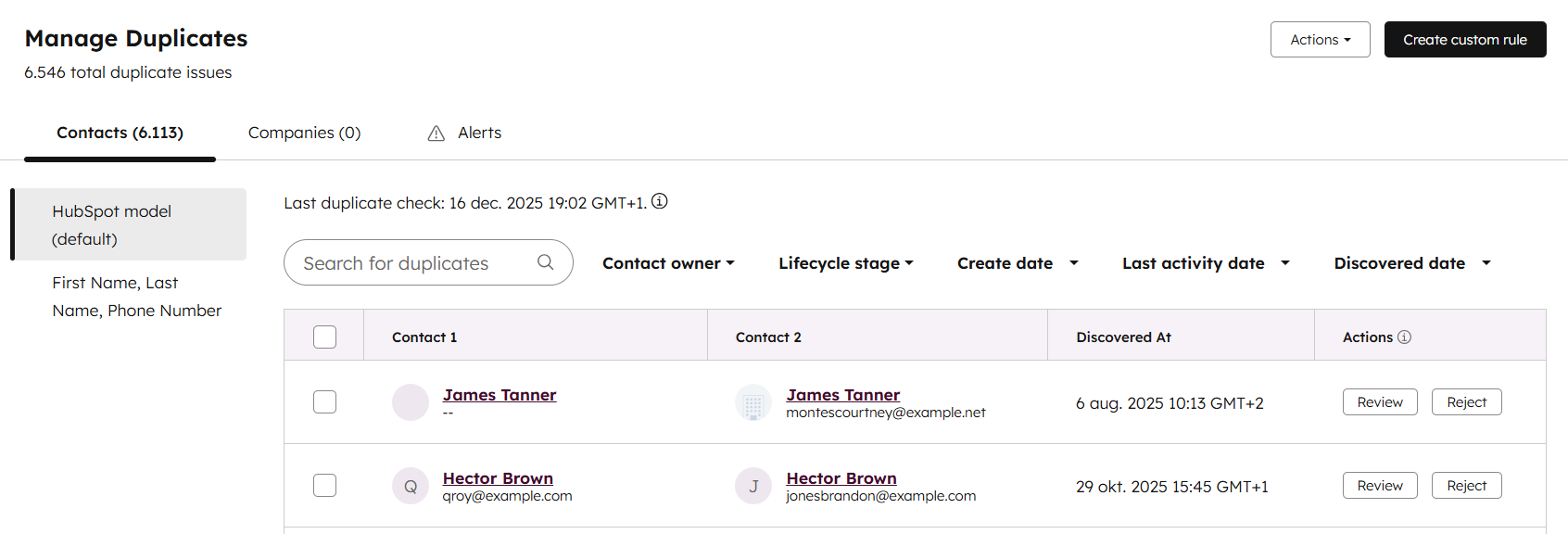
The Limits of HubSpot’s Native Deduplication Tools
HubSpot has made meaningful improvements to its native deduplication features in recent years.
Manual merging is more flexible, and bulk merge options now exist.
However, as Ryan explains, these tools still have clear limitations.
Native deduplication works best when:
-
Contact volumes are relatively small
-
Data structures are simple
-
Teams can tolerate manual review
For mid-market and enterprise teams, challenges quickly emerge:
-
Limited matching logic
-
Risky auto-merge criteria
-
Little control over how merges are triggered
“I would be extremely hesitant to turn on auto-merge with such limited logic.”
When merges happen incorrectly, the cost isn’t just bad data, it’s lost trust and broken processes.
Why Many Teams Still Choose Third-Party Deduplication Tools
Despite improvements in native functionality, many teams turn to third-party tools for one reason: precision.
Advanced deduplication solutions allow teams to:
-
Define exactly what qualifies as a duplicate
-
Control which record becomes the primary
-
Merge records via workflows and segmentation
-
Append values instead of overwriting important data
Ryan put it simply:
“Email validation and deduplication are the first two things I install in every portal.”
For teams that rely on accurate reporting, automation, and attribution, this level of control isn’t optional—it’s essential.
Why Native-Feeling Tools Matter
Another recurring theme in the conversation was friction.
Tools that operate outside of HubSpot often introduce unnecessary complexity.
External tools can lead to:
-
Context switching
-
Lower adoption
-
Forgotten cleanup routines
As HubSpot continues to consolidate marketing, sales, and service into a single platform, teams increasingly expect supporting tools to feel native.
“If users can’t tell they’re using a third-party tool, you’ve done it right.”
Native-feeling solutions reduce onboarding time, increase adoption, and ensure data cleanup becomes part of daily operations—not a forgotten side task.
Deduplication Is Not a One-Time Project
A common mistake teams make is treating data cleanup as a one-off initiative.
“You’re playing Whack-a-Mole.”
Without ongoing processes, duplicates return, invalid emails accumulate, and reporting issues resurface within months. Sustainable data quality requires automation, clear rules, and regular attention.
Clean data isn’t a project you complete—it’s a system you maintain.



